RDSの大復習。
データベースの正規化とは
正規化とは一定の規則にしたがい、データを変形し利用しやすくすることである。
データベースにおける正規化とはデータの重複をなくし、整合的にデータを取り扱えるようにするため、IDなどの一意のデータを正規系としてデータが重複しないようにテーブルを分離する設計のことを意味する。
統計や機械学習などの文脈では正規化は値の範囲を0〜1の数値にして計算しやすくすることである。
文脈によって大きく意味が異なるように見えるが、いずれも辞書的な意味は満たしているよ。
正規化されていないデータベースはひとつのテーブルで表現するかたちになり、正規化されているデータベースは複数のテーブルをIDなどで管理(リレーション)し、複数のテーブルが使用されているものになる。
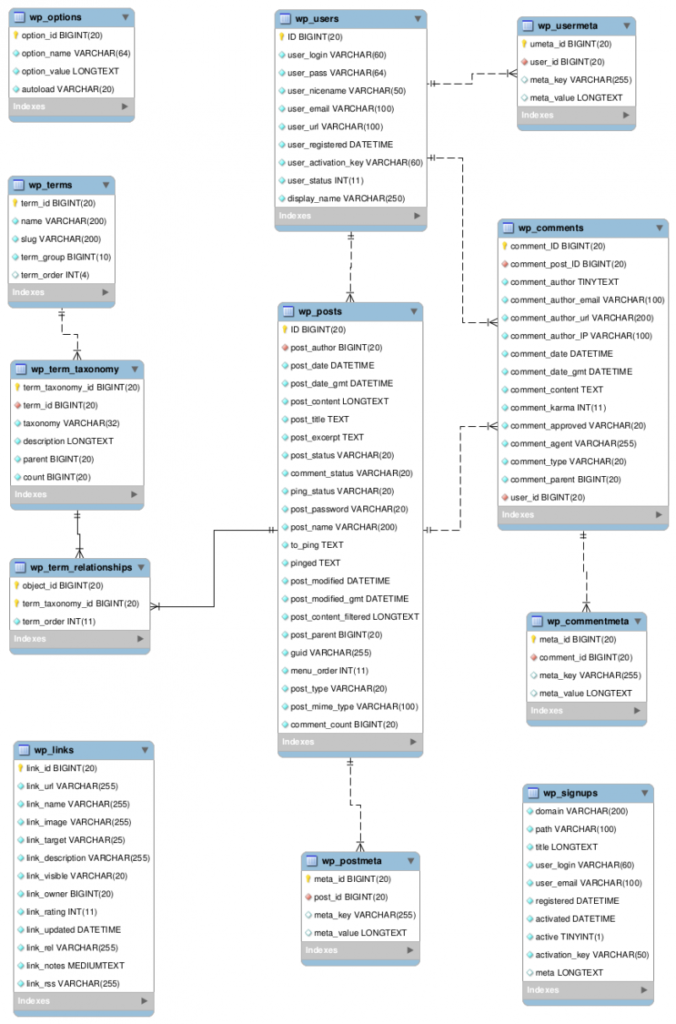
WP 3.9.4 データベース関連図(ER図)
引用:https://wpdocs.osdn.jp/%E3%83%87%E3%83%BC%E3%82%BF%E3%83%99%E3%83%BC%E3%82%B9%E6%A7%8B%E9%80%A0
正規化することにより整合性が取りやすくなり、またデータの重複が起きにくくなるため、デバッグやパフォーマンスが向上する。
きちんと正規化されたデータベースでもテーブルが増える分パフォーマンスが下がることがあるが、そういった事象は技術発展により解決されることがあるため、視認性や管理性のほうがよっぽど大事なため、正規化することが推奨される。
※アクセスがかなり多い値に関しては、あえて正規化せずパフォーマンスを向上させることもあるらしい
正規化の方法
正規化は主に3ステップに分けられる。
第1正規形
主キー(プライマリーキー)を設定し、フィールドの繰り返しグループを別テーブルに分離、導出項目を取り除く(フィールドの繰り返しを避ける)。
主キーは同じフィールドのなかでユニークな値を保証するもので、NULL値は設定できず、生成から削除まで値は変更できない。
主キーは主キー専用のフィールドを用意する必要がある。
また、導出フィールド(他のフィールドの値から自動的に値を算出することができるフィールド。例えば合計金額や消費税額など)の削除を行う。
第2正規形
部分従属(ひとつの候補キーによって値が決定する関係)するフィールドを分離するため候補キーを決定し、その他のフィールドも決定できるように別テーブルに分離する。
例えば候補キーを製品番号とするとそれに従属する製品名や単価などが部分従属に値する。
第3正規形
推移従属(主キー以外のフィールドに従属している関係)するフィールドを別テーブルに分離する。
例えば、受注情報にユーザーの住所などが含まれている場合は、ユーザー情報のテーブルをつくる、などグルーピングできる要素でテーブルを分けること。
ただし、第3正規化をあまり厳密に適用しすぎるのは、運用時のパフォーマンスや作業効率に悪い影響を与える可能性があるため注意する。
分離することは可能だが、分離した際の恩恵が望めない場合や、パフォーマンスに悪影響を与えそうな場合は、わざわざ分離する必要がないことを念頭におく。
上記の3工程により、理論的には各テーブルは完全従属しているフィールドで構成されることになる。
正規化に失敗した場合は、やたらとフィールドの多いテーブルができたり、シリアライズされた配列やJSONデータを格納することになるため、なるべくそうならないように注意する。
データ型
文字列型(日付含む)や数値型など多くの方があるが、基本的には入れるデータに合わせて型設計するだけで問題ない。
型設計することでパフォーマンスが向上する。
ちなみにWordPressのカスタムフィールドの値であるmeta_valueフィールドはTEXT型でどのようなデータでも挿入できるが、その代わり数値順に並び替えたり、検索する場合に低速になっている。
ストレージエンジンの違いについて
ストレージエンジンは、その名の通りデータを処理する方法のことである。
主に、「MyISAM」あるいは「InnoDB」の2つがよく使われる。
MySQL5.5未満は「MyISAM(マイアイサム)」が標準で使用されていたが、5.5以降は「InnoDB(イノディービー)」が標準である。
WordPressでも後方互換性のため、MyISAMが標準でセットアップされるようになっていたが、いつからかWordPressセットアップ時にMySQL5.5以降はInnoDBで用意されるようになった。
そのため古いWordPressの場合は、MyISAMが使われていることが多い。
MyISAMとInnoDBの違いは下記。
InnoDBのほうが新しく、ほぼすべてのMyISAMの機能がInnoDBでは使用できるようになっているため、基本的にはInnoDBを使用したほうがいい。
MyISAM
シンプルな構造のため、メモリとCPUが高性能でなくても高速に動作する。
一方テーブル単位のロックとなっており、ロックの粒度が粗い。
InnoDB
行単位のロックであり、ロックの粒度が細かい。
さらにMVCC(MultiVersion Concurrency Control)のため、更新によりロック中の行を参照していても、更新前のバージョンを参照することでロック解除待ちの状態が不要となる。
またクラスタインデックスとなっているため、主キーのインデックスが有効になると高速なデータ検索が可能となる。
※WordPressは主キーが有効となるDB設計ではない(セカンダリインデックス)ため、さほど有効にはなっていない
またトランザクションを利用できる(WPがMyISAMでも動作する=トランザクションのロジックははWPコアで賄っている)。
トランザクションの説明はWikiの引用で失礼。
トランザクション処理では、データベースの個々の操作が自動的に1つに連結され、不可分のトランザクションとされることがある。トランザクション処理システムは、1つのトランザクション内の全操作がエラー無しに成功するか、全操作が実行されないことを保証する。一部の操作が成功し、他の操作でエラーが発生した場合、トランザクション処理システムはそのトランザクションの「全」操作を「ロールバック; roll back」し、そのトランザクションによる痕跡を消去してデータベースを一貫した状態(そのトランザクションを開始する前の状態)にリストアする。あるトランザクションの全操作が完了した場合、そのトランザクションはシステムによって「コミット; commit」され、データベースに加えられた更新内容が恒久的なものとなる。コミットされたトランザクションがロールバックされることはない。
https://ja.wikipedia.org/wiki/%E3%83%88%E3%83%A9%E3%83%B3%E3%82%B6%E3%82%AF%E3%82%B7%E3%83%A7%E3%83%B3%E5%87%A6%E7%90%86
一方、MyISAMよりCPUとメモリリソースを消費するため、低スペックのサーバーでは過負荷になることがある。
WordPressの場合、下記のようなSQL文を使用してストレージエンジンを変更できる。
# ALTER TABLE テーブル名 ENGINE = InnoDB;
ALTER TABLE wp_commentmeta ENGINE = InnoDB;
ALTER TABLE wp_comments ENGINE = InnoDB;
ALTER TABLE wp_links ENGINE = InnoDB;
ALTER TABLE wp_options ENGINE = InnoDB;
ALTER TABLE wp_postmeta ENGINE = InnoDB;
ALTER TABLE wp_posts ENGINE = InnoDB;
ALTER TABLE wp_termmeta ENGINE = InnoDB;
ALTER TABLE wp_terms ENGINE = InnoDB;
ALTER TABLE wp_term_relationships ENGINE = InnoDB;
ALTER TABLE wp_term_taxonomy ENGINE = InnoDB;
ALTER TABLE wp_usermeta ENGINE = InnoDB;
ALTER TABLE wp_users ENGINE = InnoDB;ORM – O/Rマッピング
オブジェクト指向プログラミング言語におけるオブジェクトとリレーショナルデータベース(RDB)の間でデータ形式の相互変換を行うこと。
またそのための機能やソフトウェアをO/Rマッパーという。
WordPressでいうと、get_post()関数などのデータベースにデータを挿入したりする関数である。
これを利用することで、SQL文を知らなくてもCRUD処理を書くことができるため、最近の若者はパソコンを使えないのと同じく、DB設計というものを知らない人が多いような気がする。
O /Rマッパーを自前で用意する場合、例えばテーブルを新たに作成する場合によく使用されるのは、そのテーブル構造のバージョンを別途保存しておいて、そのバージョンと見比べて新規作成するかアップデートするか、処理をしないかといったことをすることが多い。
こんな感じのO/Rマッパーの扱いのほうがイマドキのWeb制作では役に立つことが多い。
レプリケーション
アプリケーションからの更新を受け付けるマスターと、マスターから更新を受け取るスレーブによって構成され、
マスターは更新内容(差分)を連続的にスレーブに転送し、スレーブはその差分をもとにテーブルの更新をし続けることにより、マスターとスレーブのデータが同一になるという仕組みのこと。
MySQLのレプリケーションは1:Nの構成をとることができ、ひとつのマスターへ行われた更新を多数のスレーブに転送することができる。
この特性を利用して、更新以外の参照系のクエリをスレーブで処理することにより負荷分散を行うという使い方がよくされている。
多くのスレーブを持つことで、ネットワーク転送量が増えてしまうが、スレーブからさらに他のスレーブへ更新を転送するといったように多段階の構成をとることにより、緩和することが可能である。
また、2つのMySQLサーバーがお互いにお互いのスレーブになるというマルチ・マスター型のトポロジにすることも可能である。
さらにスレーブは、マスターで障害発生時に処理を代行したり、地理的に離れた地点間で行うディザスタリカバリ(災害復旧)、バックアップ用途、負荷の高いレポーティング用のクエリを実行するといった使い方がなされているなど、負荷分散だけでなく、可用性などの側面でも柔軟性が高い。
その分多くのトラブルのもとがレプリケーションに関するものなので、その仕組みを正しく理解することが不可欠である。